
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 논문
- V3
- python
- 네트워크
- 언어모델
- 논문리뷰
- 딜러닝
- 딥러닝
- modbus-tcp
- connx
- 파이썬
- yolo
- CycleGAN
- Protocol
- 게임개발
- ctypes
- Detectron2
- 리뷰
- 호흡분석
- modbus-rtu
- 프로그래머
- 이터널리턴
- 설치
- pyqt5
- trapmessage
- ChatGPT
- 개발자
- C언어
- 헬스케어
- 언리얼엔진
- Today
- Total
yusukaid's IT note
Pytorch를 이용한 YOLO v3 논문 구현 #0 - YOLO 구조 파악하기 본문
※본 포스팅은 아래 블로그를 참조해 번역하고 공부한 것입니다.
https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
Tutorial on implementing YOLO v3 from scratch in PyTorch
Tutorial on building YOLO v3 detector from scratch detailing how to create the network architecture from a configuration file, load the weights and designing input/output pipelines.
blog.paperspace.com
위 블로그는 YOLO v3를 pytorch로 구현했으며, 이를 총 5개의 파트로 나눴습니다.
#0에서는 YOLO의 작동 원리와 구조를 복습하는 시간을 가져보겠습니다.
읽기 전에 밑 포스팅을 참고하시면 좋을 것 같습니다.
https://it-the-hunter.tistory.com/25
YOLO란 무엇인가?
카메라에 비춰진 사물의 영역을 표시하고 인식된 사물이 무엇인가에 대해 알려주는 모델이 바로 YOLO이며, You Only Look Once의 약자이다. 현재 YOLO 모델은 버전이 5까지 나와있지만, 학술적으로는 4
it-the-hunter.tistory.com
A Fully Convolutional Neural Network
YOLO는 Convoulutional layers (합성곱 레이어)를 사용하여 Fully convolutional neural Network (이하 FCN)을 생성한다. 총 75개의 레이어를 갖고 있다. FCN의 최대 장점은 input 이미지의 크기에 영향을 받지 않는 것이다. 그러나 사실상 일정한 크기를 고집한다. 이는 알고리즘을 실행할 때, head에서 여러 문제들이 보이기 때문이다. 가장 큰 문제는 이미지를 배치 처리할 때 모든 이미지가 고정된 높이와 폭을 가져야 한다는 것이다.
YOLO의 신경망은 stride라는 인자에 의해 이미지가 down smapling된다. 본 구현에서는 stride=2인 레이어가 사용된다. 이 때문에 low level features의 손실을 방지할 수 있다.
출력값 이해하기
일반적으로 convolutional layer에서 학습된 features는 객체를 예측하는 classifier/regressor로 전달된다.
여기서는 1x1 convolution layer를 이용하여 예측을 진행한다. 1x1 convolution을 사용하기 때문에, prediciton map (예측 map)은 정확히 feature map의 크기이다. 이는 각 cell이 바운딩 박스의 고정된 숫자를 예측한다고 이해하면 편하다.
최종적으로 feature map에 Bx(5+C)가 저장된다. 논문에 의하면 B (바운딩 박스)는 특정 객체를 탐지하는 데 있어 전문화 되어 있다. 각 바운딩 박스들은 5+C와 C (class confidences)를 속성으로 갖고 있다. YOLO v3는 모든 cell이 3개의 바운딩 박스를 예측한다.
feature map의 각 cell은 객채의 중심이 해당 cell의 수용 영역 ( receptive field) 에 맞아 떨어지면 바운딩 박스를 통해 객체를 예측한다.
하나의 바운딩 박스는 특정 객체를 탐지하며, 어떤 cell이 바운딩 박스를 갖고 있는지 알아야 한다. 따라서 input 이미지를 feature map과 동일한 차원의 grid로 분할한다.

위 예제의 이미지는 416x416이고 stride는 32이다. stride가 32이 일 때 feature map의 차원은 13x13이 된다. 따라서 input 이미지를 13x13 cell로 분할한다. 그 후 객체의 ground truth box (정답 영역 박스)의 중앙을 포함하는 cell이 객체를 예측하기 위해 선택된다. 위 예제에서 cell은 빨간색이다.
이제 빨간 cell은 grid에서 7번째 행의 7번째 cell이다. 객체 '개'를 탐지하는 것으로써 feature map의 7번째 행, 7번째 cell로 할당된다.
결과적으로 cell은 3개의 바운딩 박스를 예측할 수 있다. 하나는 객체 '개'의 ground truth lable로 할당되었다. 이를 이해하기 위해서는 anchor의 개념도 살펴보자.
Anchor Boxes
최근 object detection은 미리 정의된 기본 값 바운딩 박스 anchors를 사용한다. YOLO v3에서는 각 cell에서 3개의 바운딩 박스를 예측하기 위한 3개의 anchor를 가진다.
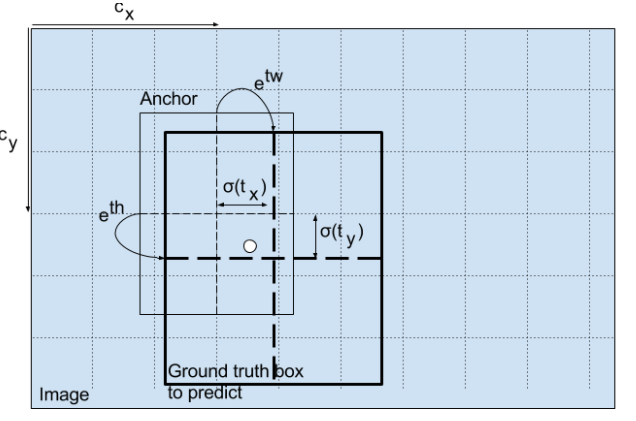
신경망의 output의 바운딩 박스 예측값을 얻기 위한 수식이다.
- bx: 예측값의 x 좌표
- by: 예측값의 y 좌표
- bw: 예측값의 w 좌표
- bh: 예측값의 h 좌표
- tx, ty, tw, th: 신경망의 output
- cx, cy: grid의 좌측 상단 좌표
- pw, ph: 박스에 대한 anchor 차원
중장 좌표의 예측은 sigmoid 함수를 이용한다. 출력값을 0에서 1이 되도록 하기 위함이다. 또한 일반적으로 YOLO는 바운딩 박스의 완벽한 중심 좌표를 예측하지 않는다. 두 가지 이유가 있다.
- 객체를 예측하는 grid cell의 좌측 상단 좌표와 연관이 깊다.
- feature map으로부터 cell의 차원이 1로 정규화 된다.
만약 예측된 값들이 1보다 크면, 설계한 YOLO 알고리즘에 어긋난다. 객체의 중심이 cell에 놓이지 않고 그 위나 옆에 있는 cell에 놓이기 때문이다. 그러므로 이 문제를 방지하기 위해 sigmoid 함수를 이용한다. 예측하는 grid에 효과적으로 중심이 위치할 수 있다.
Bounding box
바운딩 박스는 output에 log-space 변환을 적용하여 예측할 수 있다.
예측된 bw, bh는 이미지의 높이와 넓이로 정규화된다. 따라서 위 예제에서 객체 '개'를 포함하는 바운딩 박스에 대한 예측 좌표가 (0.3, 0.8)이면 stride=32에서 (13x0.3, 13x0.8)이 실제 높이와 넓이가 된다.
Objectness Score
객체 점수는 바운딩 박스에 객체가 포함되어 있을 확률을 의미한다. 빨간색 및 grid에 인접할수록 1에 가까워진다.
Class Confidences
검출된 객체가 특정 class를 지니고 있을 확률이다. v3이전 YOLO에서는 softmax함수가 사용됐다.
하지만 v3로 넘어오면서 그 특징은 사라졌고, 대신에 sigmoid를 이용하기 시작한다. softmax를 사용할 경우 각 class들은 상호 배타적으로 가정한다. 하나의 class를 갖고 있으면 다른 class를 지니지 않는다는 것이다. 이는 여러가지 객체를 검출 할 수 없다는 뜻이다. 따라서 다수의 객체를 검출하기 위해 sigmoid 함수를 적용했다.
다른 Scale에서 예측
YOLO v3는 3개의 다른 scale에서 예측한다. detection layer는 각각 stride=32, 16, 8을 지닌 서로 다른 크기의 feature map에서 검출하기 위해 사용된다. 예를 들어 416x416 input이 진행됐을 때, 13x13, 26x26, 52x52 규모로 객체 탐지가 진행된다.

이 scale을 변화해주는 작업은 YOLO v3가 작은 물체와 이전 YOLO에서 빈번히 발생한 에러를 줄여주고 보다 객체를 잘 감지할 수 있다. Upsampling은 신경망이 작은 물체를 탐지하는 데 세밀한 feature를 학습하는데 도움을 줄 수 있다.
Thresholdsing by Object Confidence
output의 바운딩 박스 개수는 상당히 많다. 하지만 예제 이미지의 경우 객체는 '개'로 하나만 있다. 탐지 output의 수를 줄이는 방법은 바로 NMS이다.
https://it-the-hunter.tistory.com/44
[딥러닝]정확한 객체 검출을 위한 NMS
dfdf
it-the-hunter.tistory.com
YOLO v3는 공식적으로 coco dataset을 이용해 신경망을 학습했으며, 공식적으로 제공되는 가중치 파일 yolov3.weights를 이용한다.
다음 챕터에서는 신경망 구조의 이해와 레이어 구현을 다룬다.
'YOLO' 카테고리의 다른 글
| Pytorch를 이용한 YOLO v3 논문 구현 #2 - 신경망 순전파 구현 (0) | 2022.09.27 |
|---|---|
| Pytorch를 이용한 YOLO v3 논문 구현 #1 - 신경망 구조의 계층 생성 (22.10.04 수정) (0) | 2022.09.27 |
| TensorFlow를 이용한 YOLO v1 논문 구현 #10 - 리뷰 (0) | 2022.07.12 |
| TensorFlow를 이용한 YOLO v1 논문 구현 #9 - 최종 실행 및 결과 확인 (0) | 2022.07.08 |
| TensorFlow를 이용한 YOLO v1 논문 구현 #8 - evaluate.py (0) | 2022.07.08 |



