

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- V3
- 이터널리턴
- 언리얼엔진
- ChatGPT
- MODbus
- 게임개발
- 네트워크
- Detectron2
- ctypes
- SNMP
- modbus-rtu
- 파이썬
- 개발자
- trapmessage
- 딥러닝
- yolo
- python
- 프로그래머
- modbus-tcp
- 논문리뷰
- 논문
- 언어모델
- 딜러닝
- 호흡분석
- C언어
- Protocol
- 리뷰
- connx
- 헬스케어
- 설치
- Today
- Total
yusukaid's IT note
YOLO란 무엇인가? 본문
카메라에 비춰진 사물의 영역을 표시하고 인식된 사물이 무엇인가에 대해 알려주는 모델이 바로 YOLO이며, You Only Look Once의 약자이다. 현재 YOLO 모델은 버전이 5까지 나와있지만, 학술적으로는 4까지만 인정이 된다고 한다..
[Object Detection]
객체 검출은 영상처리 분야에서 기본적으로 많이 쓰이는 분야이다. 얼굴 인식, 음성 인식 같은 분야에서 자주 보인다.
개념적으로는 여러 사물을 '어떤 것이다'라고 분류하는 (Multi-Labeled) Classification과 그 사물이 어디 있는지 박스를 통해 위치 정보를 나타내는 localization 문제를 해결하는 부분이다.
원래는 CNN을 통해 위와 같은 문제를 해결할 수 있으나, 하나의 물체를 분류하고 다시 전체 이미지를 훑는 과정의 시간이 굉장히 오래 걸린다는 단점 또한 있다. 그래서 윈도우의 일부만을 활용해 객체 탐지를 효율적으로 하기 위해 개발된 방법이 있다.
[1, 2-stage Detector]
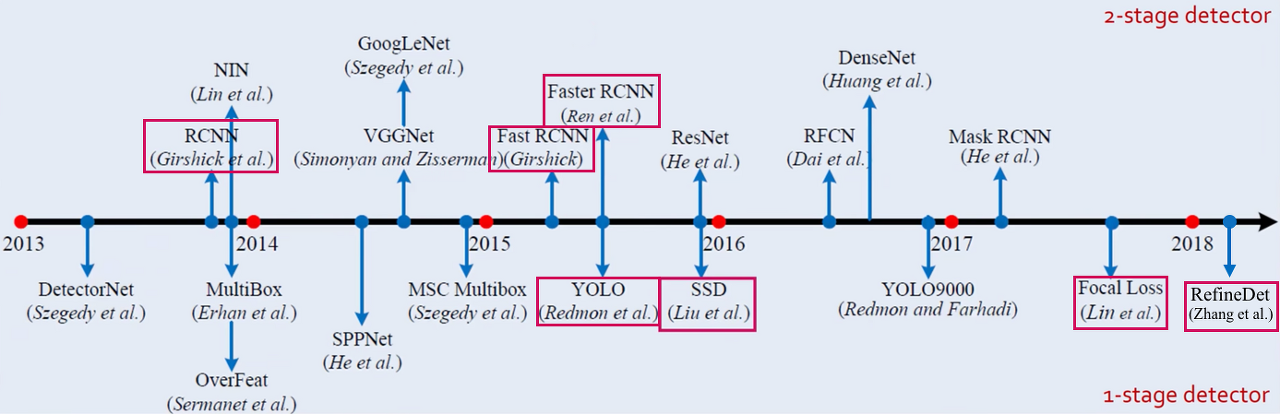
위 사진은 현재까지 영상 처리 및 딥러닝에 활용된 모델의 연표이다. 우리가 공부할 것은 YOLO 모델이지만, 그 바탕이 되는 1, 2-stage detector에 대해서 알아보자.
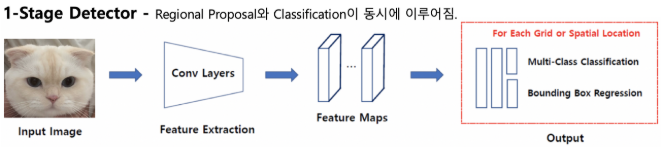
1-stage Detector는 Classification과 localization 문제를 동시에 해결한다. 속도가 빠르다는 장점이 있지만 동시에 정확성이 떨어진다는 단점 또한 존재한다.
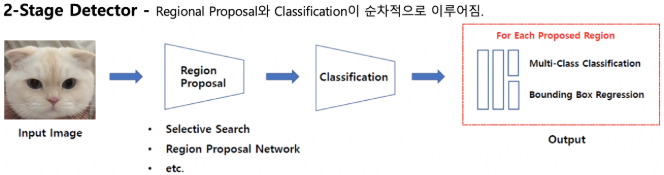
2-stage Detector는 두 문제를 순차적으로 해결한다. 당연히 속도는 느리지만 정확성은 1에 비해 높다.
우리가 공부할 YOLO 모델은 이 중 1-stage Detector에 해당한다.
[YOLO]
YOLO는 Object Detection 분야에서 널리 쓰이며, 1-stage Detector 방식을 처음으로 고안해 실시간 객체 검출이 가능한 모델이다.
YOLO의 장점 세 가지는 다음과 같다.
- 이미지 전체를 한 번만 훑는다. 여러장으로 분할해 분석하는 CNN과 다르다.
- 통합된 모델을 사용해 활용이 간단하다.
- 기존 모델보다 속도가 빨라 빠른 객체 검출이 가능하다.
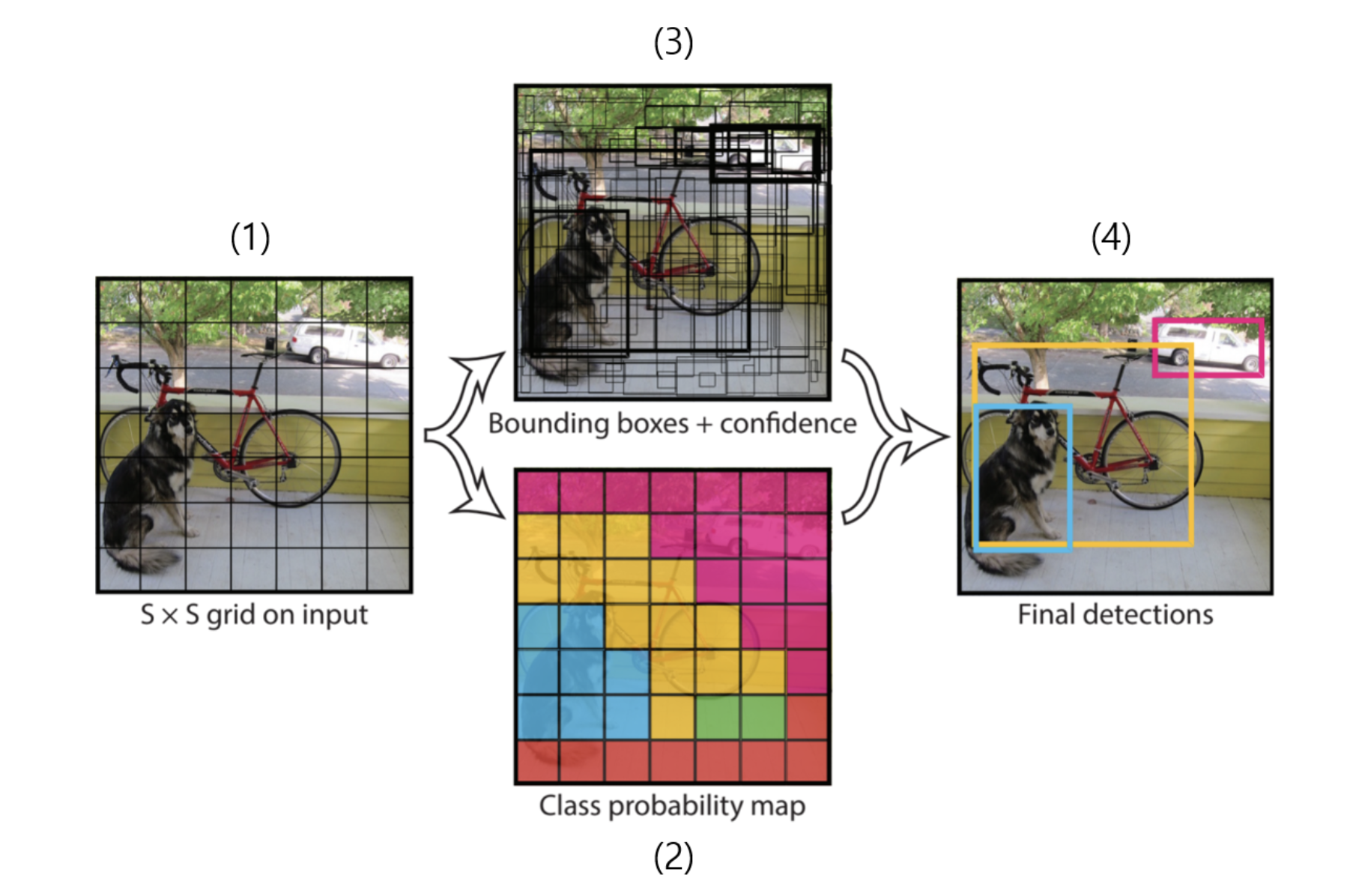
YOLO 모델의 객체 검출은 이렇게 진행된다.
- 입력 이미지를 S x S 그리드 영역으로 나눈다. 입력 이미지가 네트워크를 통과하면 (2), (3)과 같은 데이터를 얻는다.
- 각각의 grid cell은 Bounding box와 Confidence score를 갖는다. confidence score는 이 시스템이 물체를 포함한다는 예측을 얼마나 확신하는지, 박스에 대한 예측이 얼마나 정확할지를 의미한다. 만약 cell에 객체가 존재하지 않으면 confidence score는 0이 된다. 각 grid에서 중심을 그리드 안쪽으로 하면서 크기가 일정하지 않은 bounding box를 생성한다. 이 중 bounding box 안쪽에 어떤 객체가 있을 것 같다고 확신할지, 즉 confidence score가 높을수록 박스가 굵게 그려진다.
- 각각의 boundig box는 x, y, h, w와 confidence로 구성된다. 이 값들은 모두 (0, 1) 범위의 값으로 정규화한다.
- 각각의 grid cell은 C(conditional class probablity)를 갖는다.
- 평가할 때 conditional class probablity와 각 박스의 class-specific confidence score를 주는 confidence prediction을 곱한다. 이 점수는 class가 박스 안에 포함되는지와 박스가 물체에 얼마나 적합한가를 모두 포함한다.
- 이후 높은 confidence score를 가진 위치를 선택해 객체 카테고리를 선정한다.
'YOLO' 카테고리의 다른 글
| TensorFlow를 이용한 YOLO v1 논문 구현 #5 - utils.py (0) | 2022.07.08 |
|---|---|
| TensorFlow를 이용한 YOLO v1 논문 구현 #4 - datasets.py (0) | 2022.07.08 |
| TensorFlow를 이용한 YOLO v1 논문 구현 #2 - 모델 설명 (0) | 2022.07.07 |
| TensorFlow를 이용한 YOLO v1 논문 구현 #3 - loss.py (0) | 2022.07.07 |
| TensorFlow를 이용한 YOLO v1 논문 구현 #1 - 개요 (0) | 2022.07.06 |

